※ 'LLM을 활용한 실전 AI 애플리케이션 개발' 책을 정리한 내용입니다.
분산학습
GPU를 여러 개 활용해 딥러닝 모델을 학습시키는 것을 말한다. 분산 학습의 목적은 모델 학습 속도를 높이는 것과 1개의 GPU로 학습이 어려운 모델을 다루는 것이다. 모델이 작아 하나의 GPU에 올릴 수 있는 경우 여러 GPU에 각각 모델을 올리고 학습 데이터를 병렬로 처리해 학습 속도를 높일 수 있다. 이를 데이터 병렬화(data parallelism)이라고 한다.
하나의 GPU에 올리기 어려운 큰 모델의 경우 모델을 여러 개의 GPU에 나눠서 올리는 모델 병렬화(model parallelism)을 사용하는데, 딥러닝 모델의 층(layer) 별로 나눠 GPU에 올리는 파이프라인 병렬화(pipeline parallelism)와 한 층의 모델도 나눠서 GPU에 올리는 텐서 병렬화(tensor parallelism)이 있다.

파이프라인 병렬화의 경우 모델의 층 순서에 맞춰 순차적으로 연산하면 결과를 얻을 수 있다. 하지만 텐서 병렬화의 경우 하나의 층을 나눠 서로 다른 GPU에 올리기 때문에 병렬화 전과 후에 동일한 결과를 얻을 수 있을까? 그 해답은 행렬을 분리해도 동일한 결과를 얻을 수 있는 행렬 곱셈을 적용한다.
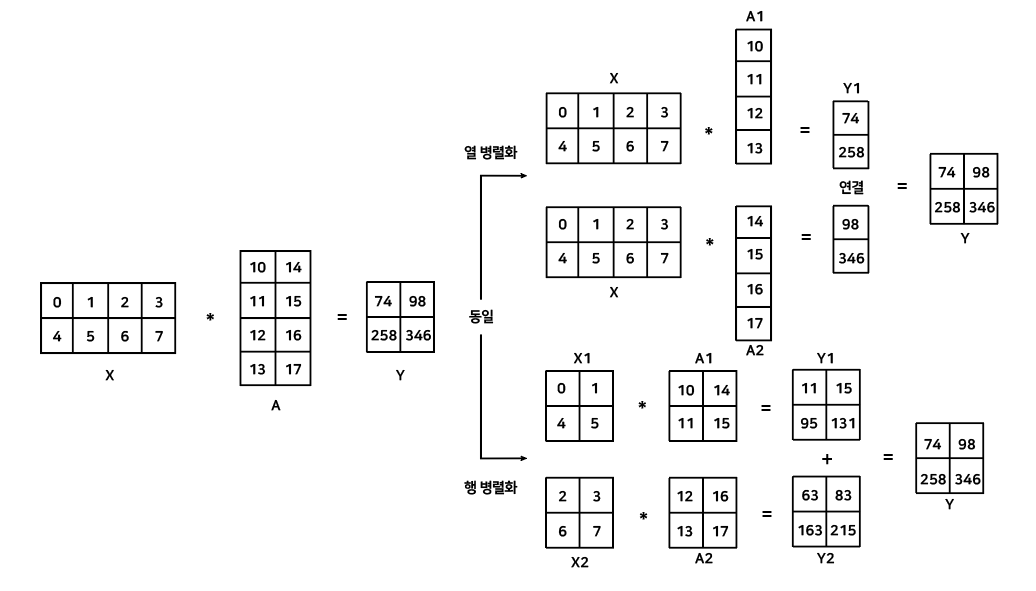
입력 X와 모델 가중치 A를 곱해 결과 Y를 도출하는 기본 연산으로 모델의 가중치를 한 열씩 분리하는 경우 입력 X와 모델 가중치를 분리한 A1,A2를 곱하고 그 결과인 Y1과 Y2를 하나로 연결해 결과를 나타낼 수 있다. 모델 가중치를 행 방향으로 분리하는 경우, 입력 X와 모델 가중치 A를 모두 분리해 X1과 A1을 곱하고 X2와 A2를 곱해 더함으로써 기존과 동일한 연산을 수행할 수 있다.
ZeRO(Zero Redundancy Optimizer)
마이크로 소프트에서 개발한 것으로 동일한 모델을 여러 GPU에 올려 중복으로 메모리를 차지하는 문제를 해결하기 위해서 만들어진 기술이다. 하나의 모델을 하나의 GPU에 올리지 않고 모델 병렬화처럼 모델을 나눠 여러 GPU에 올리고 각 GPU에서는 자신의 모델 부분의 연산만 수행하고 그 상태를 저장하면 메모리를 효율적으로 사용하면서 속도도 빠르게 유지할 수 있다는 컨셉이다.
ZeRO는 각 GPU가 모델을 부분적으로 가지고, 필요한 순간에만 모델 파라미터를 복사해 연산을 수행하는 방식으로 메모리를 효율적으로 사용한다. ZeRO는 GPU를 많이 사용할수록 각 GPU당 사용하는 메모리가 줄어든다.